Terraform Cost Estimation in 2021: The Definitive Guide
Learn more about Infracost, Scalr and Terraform Cloud providers

- Terraform cost estimators calculate deployment cost by calling the cloud provider's pricing APIs from your templates and can display results in pull request comments, CLI output, or policy frameworks.
- This 2021 comparison covers three providers for AWS: Infracost, Scalr, and Terraform Cloud; an editor's note flags that Scalr has since moved to run-based pricing and Terraform Cloud to a resources-under-management model.
- Infracost is free and open source, installed as a binary or in CI/CD, and had the best AWS resource coverage, while Scalr and Terraform Cloud bundle cost estimation into their remote operations backends.
- In an accuracy test on three AWS resources, Infracost and Scalr matched the AWS reference price exactly while Terraform Cloud slightly underestimated each.
- For policy-as-code, Infracost has no integration, Scalr integrates natively with Open Policy Agent, and Terraform Cloud integrates with Sentinel.
Editor's note (2026): This 2021 comparison reflects Scalr's and Terraform Cloud's pricing at the time. Both have since changed. Scalr now uses run-based pricing (you pay per run, not per user, free up to 50 runs/month), and Terraform Cloud moved to a resources-under-management (RUM) model. The figures below are kept for historical context; see Scalr's current pricing for today's model.
According to DevOps.com, $6.6 billion were wasted on oversized cloud resources in 2020. Part of why: teams can't see what a deployment costs before they ship it, and most don't have guardrails in place to catch the expensive ones.
If you've moved to infrastructure as code, and Terraform in particular, a few tools help you head off that kind of waste. Terraform cost estimators figure out what a deployment will cost by reading your Terraform templates and calling the cloud provider's pricing APIs. What you get back is a breakdown of resource cost and how it changes compared to the current state. You can show it in pull request comments or CLI output, or feed it into a policy framework like Open Policy Agent or Sentinel.
In this article, we review the three main providers of cost estimation for Terraform: Infracost, Scalr and Terraform Cloud. We kept this guide to AWS, but these tools also support Google (Infracost, Scalr, Terraform Cloud) and Azure (Terraform Cloud). For the full list of resources each one covers, check their docs (Infracost, Scalr, Terraform Cloud).
The goal is to help you decide which of these three providers fits your use case. We'll look at the setup process, the pricing, the resource coverage, the accuracy of the estimates, and how each one integrates with policy-as-code frameworks.
Summary
| Infracost | Scalr | Terraform Cloud | |
|---|---|---|---|
| Pricing (as of 2021) | Free | Free up to 5 users, $20/user/month starting 6 users (Scalr is now per-run) | $70/user/month |
| Installation | Binary | Integrated | Integrated |
| Policy As Code Framework Integration | None | Open Policy Agent | Sentinel |
Set up
Infracost
Infracost is free and open source. It must either be installed on your local machine (which is great for getting started or testing) or integrated into your CI/CD pipeline through GitHub Actions or Jenkins for example.
Scalr & Terraform Cloud
Scalr and Terraform Cloud work differently from Infracost. They aren't cost estimation tools on their own. They're remote state and operations backends that happen to include cost estimation, alongside automation and collaboration features for Terraform. To estimate Terraform costs with Scalr and Terraform Cloud, you'll first need to estimate how many runs you need, then head to the Scalr sign-up page to see your cost estimates.
Create a free Terraform Cloud account
User Experience
Infracost
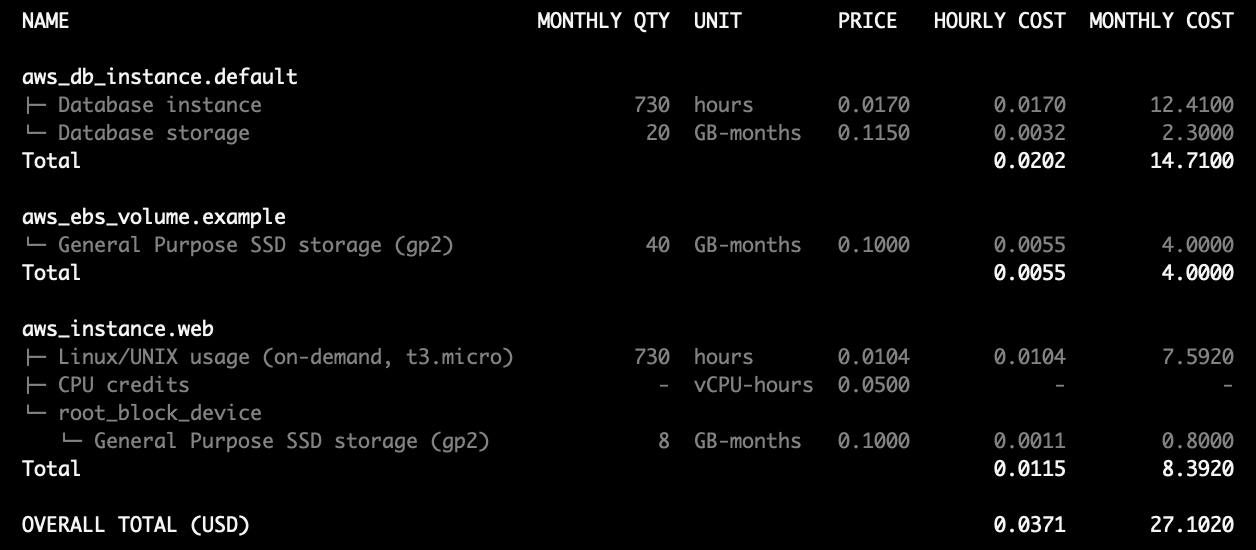
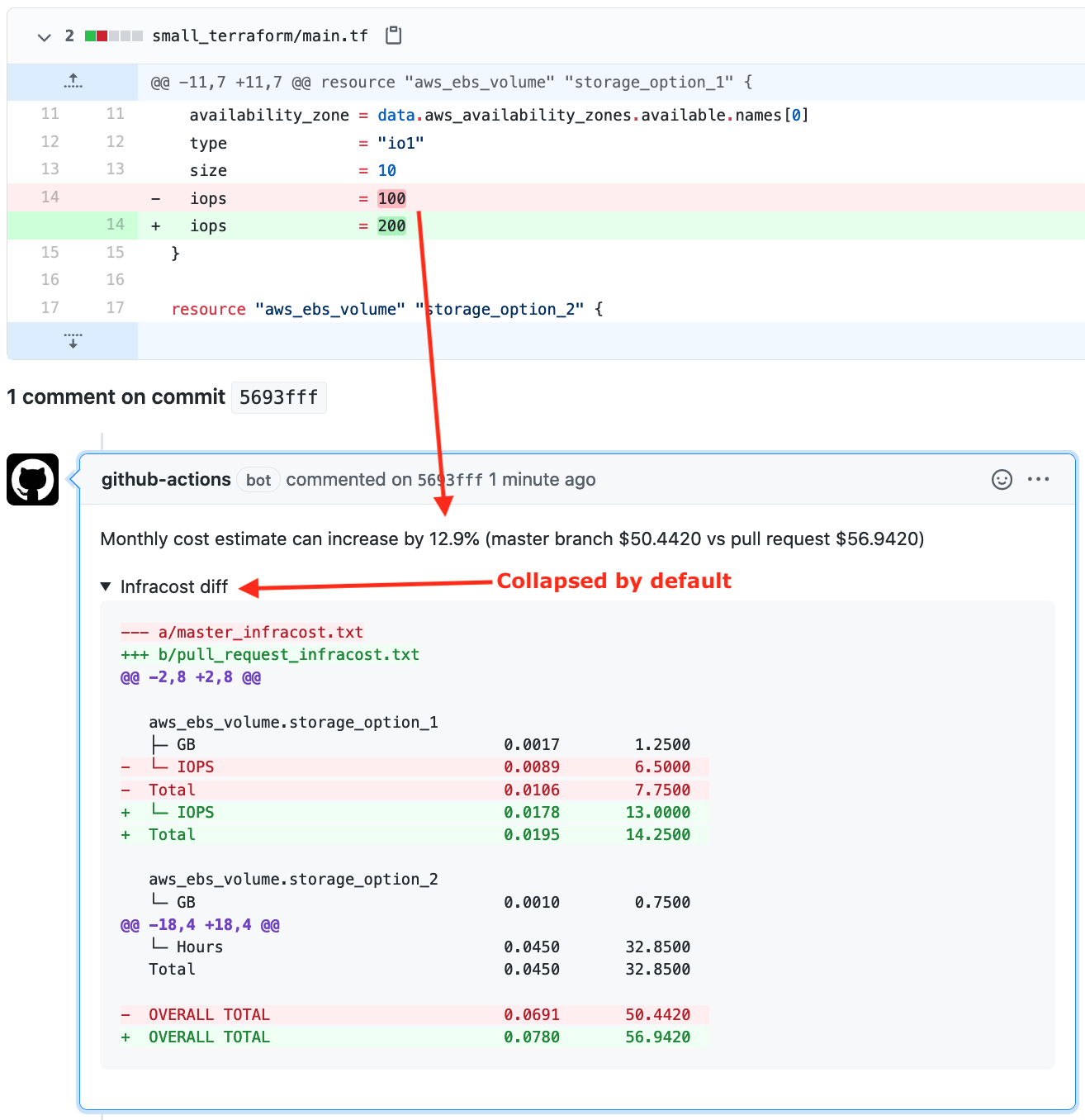
To run Infracost, just type the infracost command in the Terraform root directory. It shows a detailed monthly cost estimate, broken down by resource. It can also post that estimate to a pull request comment, where you can see how the cost changes against the current state.
Scalr
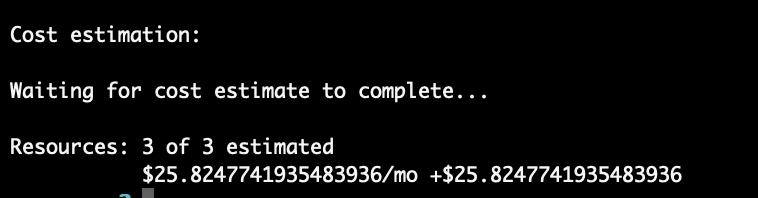
Scalr runs cost estimation automatically during the plan and apply phases. It shows the monthly cost estimate and how it's changed since the previous state, both in the Scalr UI (for all runs) and in the CLI (for CLI-triggered runs).

Terraform Cloud
Like Scalr, Terraform Cloud shows the monthly cost estimate and how it's changed since the previous state, in both the UI and the CLI.
Price accuracy
We ran a quick experiment to see how accurate the estimates were against the AWS reference price, using three resources that all providers support. Infracost and Scalr both nailed the correct cost, while Terraform Cloud came in a little low every time.
| us-west-2 | AWS Reference | Infracost | Scalr | Terraform Cloud |
|---|---|---|---|---|
| aws_db_instance 20 Go MySQL db.t2.micro | $14.71 | $14.71 | $14.71 | $14.46 |
| aws_instance ubuntu t3.micro | $8.39 | $8.39 | $8.39 | $7.48 |
| aws_ebs_volume 40 Go | $4 | $4 | $4 | $3.87 |
Policy As Code Integration
Letting developers see the cost of a deployment in the CLI or a pull request before running terraform apply is useful on its own. But you can go further: set guardrails that block a deployment automatically when it goes over a cost threshold. That's the job policy-as-code frameworks do.
Infracost doesn't integrate with any policy-as-code framework, so if you want to enforce policy automatically, you'll have to wire it up yourself. Scalr integrates natively with Open Policy Agent, an open-source policy framework that works across the cloud-native stack. Here is an example of an OPA policy that checks if a cost estimate is above a certain threshold. Terraform Cloud integrates with Sentinel, Hashicorp's proprietary policy framework.
| Infracost | Scalr | Terraform Cloud |
|---|---|---|
| No | Open Policy Agent | Sentinel |
Which one should you pick?
Pick Infracost if you already run a DIY Terraform pipeline and have no plan to move it to a remote state and operations backend. It had the best coverage for AWS resources, and it can comment on pull requests with the estimation results.
Scalr and Terraform Cloud work differently. Cost estimation comes bundled into their remote operations backend, so you have to adopt one of them as your remote backend to use it. That can make sense if you're trying to standardize how your team uses Terraform and collaborate on it. The two mainly differ on pricing (at the time of writing, $20/user/month for Scalr if your team is larger than 6 vs. $70/user/month for Terraform Cloud; Scalr has since moved to run-based pricing and Terraform Cloud to a RUM model) and on the policy-as-code framework they support (Open Policy Agent for Scalr, Hashicorp's Sentinel for Terraform Cloud).
Either way, Terraform cost estimation is still pretty new, and 2021 will probably bring a lot of improvement in the resources and cloud providers these tools support.

CI/CD and GitOps for Terraform & OpenTofu
Comprehensive guide to building reliable CI/CD pipelines and implementing GitOps workflows for Terraform and OpenTofu infrastructure automation.