Terraform at Scale
Learn how to scale Terraform and OpenTofu as usage increases in your organization

Terraform or OpenTofu can be a game changer for anyone looking to improve the speed at which they deploy their infrastructure. This blog isn't just about writing Terraform code, it's about architecting solutions that can help scale your Terraform operations even for the most complex organizations. There are different personas with different problems that they face when trying to scale Terraform usage.
From a platform team perspective...
- Do you have a defined way of creating VCS repositories?
- Do you have a list of approved Terraform modules?
- How do you enforce standards and compliance?
- Do you give engineers autonomy over their workspaces?
- Do you enforce Open Policy Agent in the Terraform run pipeline?
From an engineer's perspective...
- Should you put all resources in a single monolithic Terraform deployment?
- How do you use Terraform modules to reduce duplicate code?
- Should you break the deployment up into small workspaces and Terraform modules?
- Does the organization have best practices and standards that you need to be aware of?
- Should you use a VCS workflow or use the Terraform CLI?
Many of the questions depend on the organization, and there isn't necessarily a right or wrong way to do it, but all of these areas can be hard to do at scale. The key is a common framework that can accommodate various Terraform workflows and your likely ever changing requirements in complex organizations.
Remote State or Remote Ops?
The first item to tackle when talking about scale is to define where the Terraform runs will execute and where the state will be stored. When we initially talk to most customers we hear that they are running Terraform locally or in a CD pipeline such as Github Actions. An industry best practice is to store your Terraform state in a remote backend regardless of where it runs. There are two types of remote backends, in either case, the Terraform state is stored remotely, but there are some key differences:
- Remote state storage: S3 is a good example of storing your state in basic remote state storage. The advantage of this option is getting your Terraform state out of local laptops and into something remote where the necessary admins have access to it. In this case, the Terraform applies are still executed locally, whether that is on a laptop or a CD pipeline.
- Remote operations backend: Examples of a remote operations backend would be Scalr or Terraform Cloud. Not only is your Terraform state stored remotely, but the operations are also executed remotely. When executing a Terraform run the Terraform configuration files are pulled into the backend where they go through the Terraform workflow and the result ends with a Terraform apply and the state stored remotely. The key difference here is the ability to collaborate with team members on the Terraform workspaces, introduce multi-tenancy, and integrate with the greater Terraform ecosystem
Today we are going to talk specifically about how you can scale Terraform in Scalr, but if you're interested, we do have information on the Scalr differentiators from Terraform Cloud.
Decoupling Terraform Administration and Operations
As adoption of Terraform in your organization increases, you will need to scale your implementation with it. This means you will need to figure out how to do so in a way that your platform team is not a bottleneck, which means you need to figure out a way to make your developers more autonomous while also reducing blast radius.
To make things easier, at Scalr we've built a flexible organizational model that meets the needs of various personas and business requirements. There are three scopes in the model:
- Account Scope: Think of this as an administrative control plane for your platform team.
- Environment Scope: Think of this as a landing zone, an organizational unit, or similar to a cloud provider account.
- Workspace Scope: The individual workspace where a Terraform/OpenTofu configuration is managed and runs are executed, with its own variables and settings.
If you were to compare this to AWS, the Scalr account would be an AWS master account and the Scalr environments would be similar to the AWS child accounts where infrastructure is provisioned. The hierarchy makes it very easy for you to centralize the Terraform administration while decentralizing the Terraform operations.
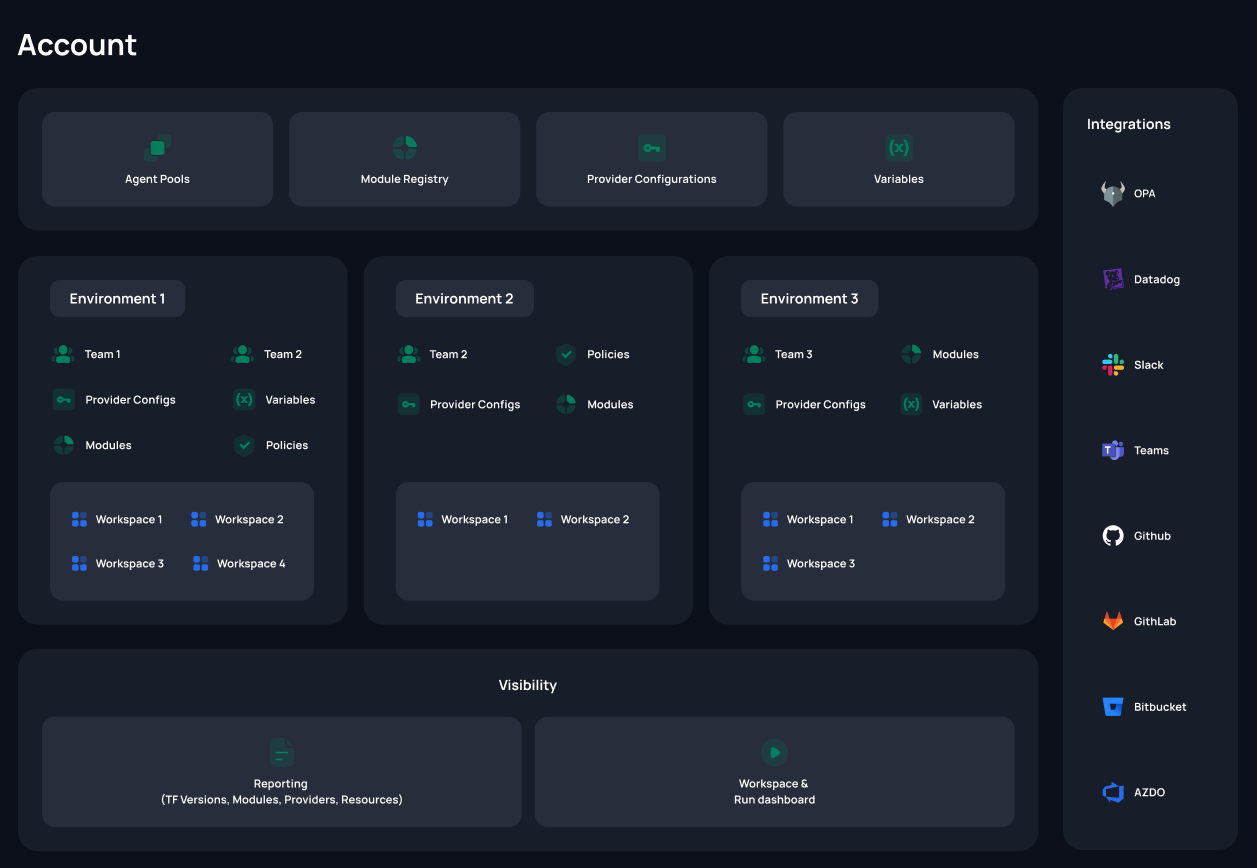
Scalr Hierarchy
Account Scope
The platform teams, who create and maintain the Scalr environments, VCS providers, provider credentials, Terraform module registry, OPA policies, teams, and self-hosted agents would mainly operate at the account scope. All of these objects can be managed from the account scope and assigned/shared with the environments as required (note: the Scalr provider can be used to manage these objects as well). The platform team can add any of these objects from the account scope and not have to be concerned about flipping back and forth between contexts to make changes.
On top of managing objects from a single location, the administrator also has reporting and operational dashboards across all environments and workspaces in a single pane of glass. Observability is invaluable for large scale deployments as seen in the Terraform module report below:
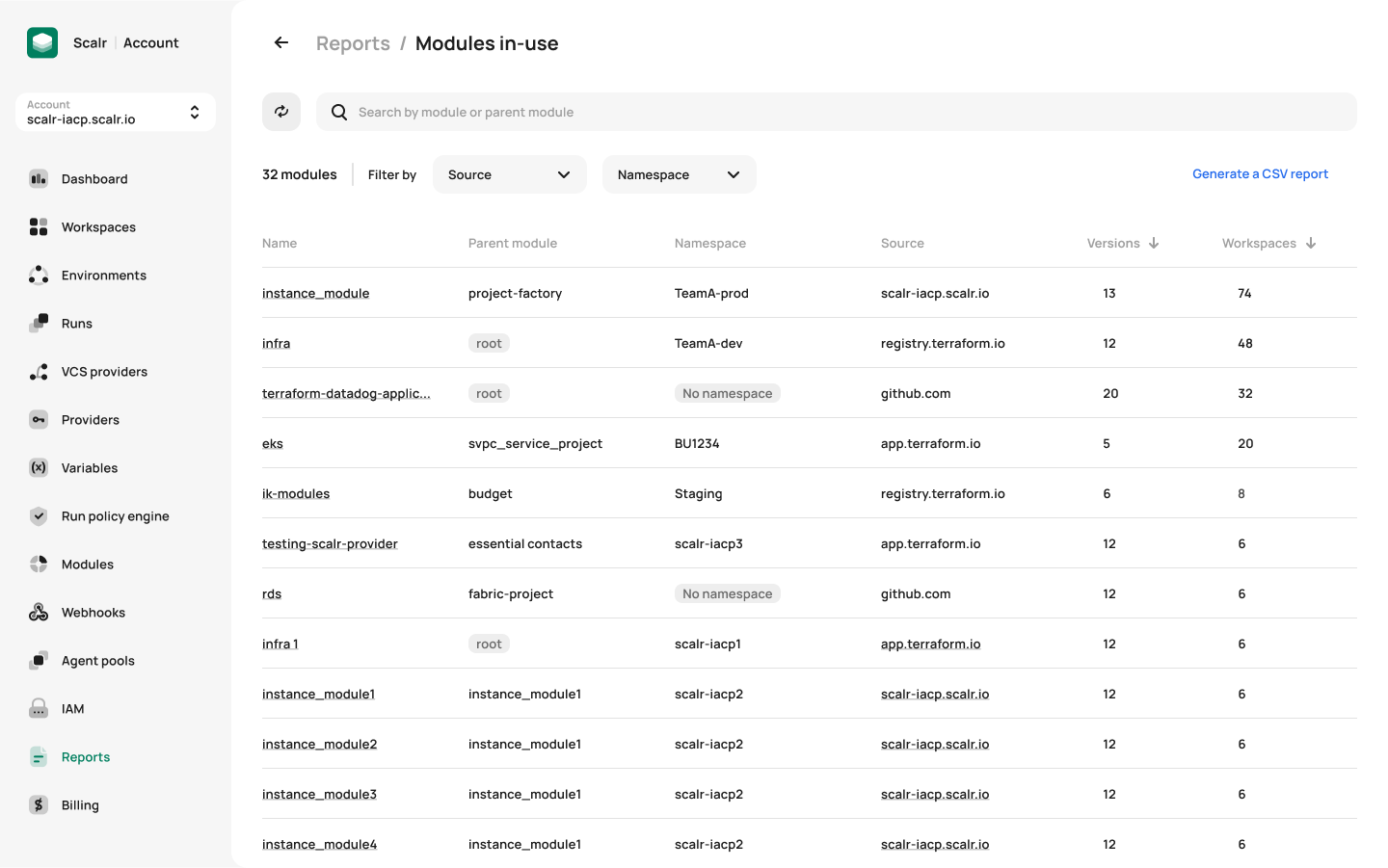
Module Registry Reports
In the example above, you can see all Terraform modules that have been deployed in Scalr as well as their versions and the source of the module, such as a private module registry. This allows you to identify modules that can be deprecated or those that are being pulled from untrusted sources. The same concept applies to Terraform providers, Terraform versions, and resources.
You may also want to know which workspaces are stale and need to be updated. Rather than searching through the lower level environments, as an admin, you can see all of this at the account scope:
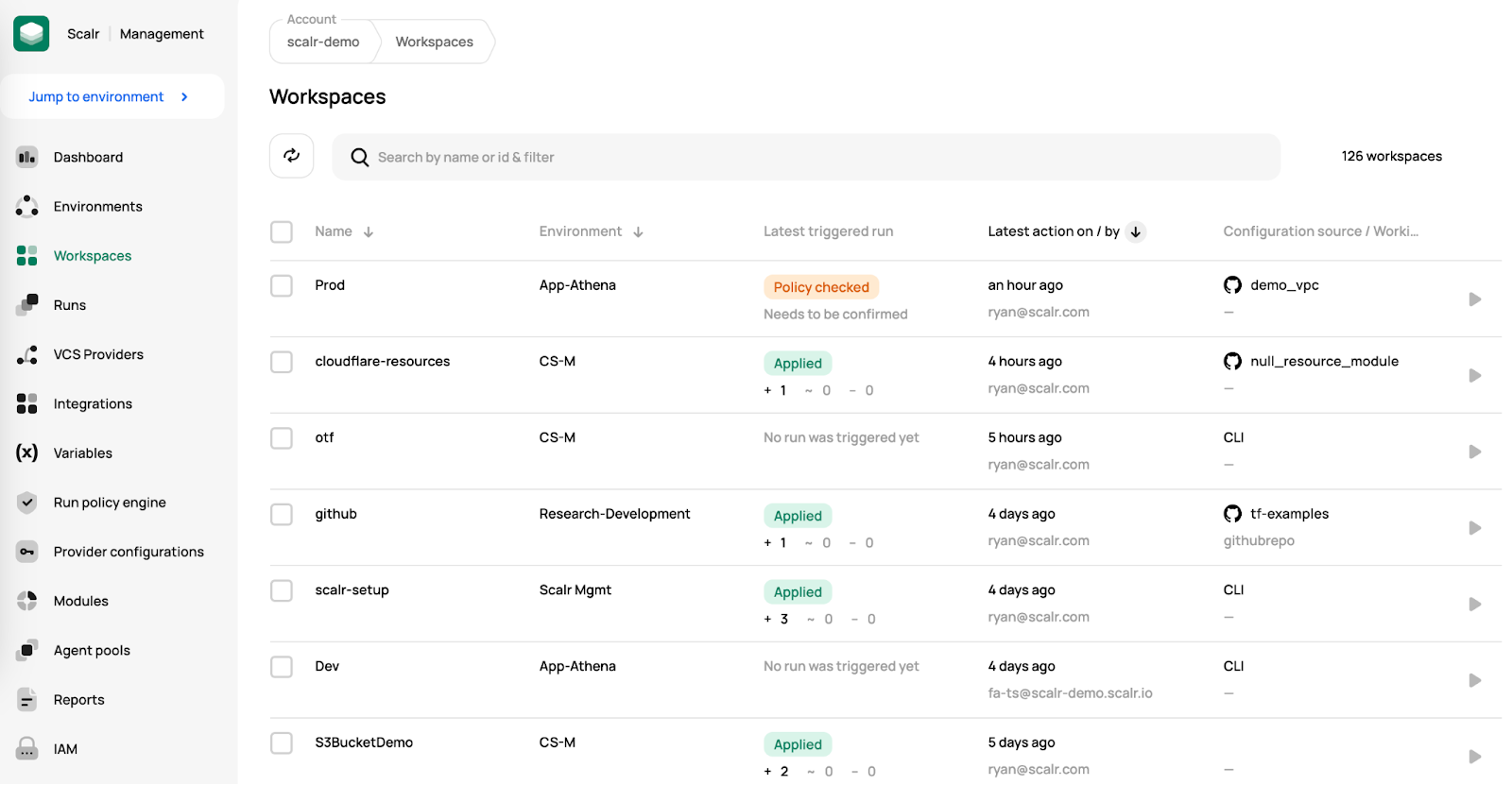
Observe Environment & Workspace Usage
Lastly, how are all of the environments and workspaces operating? Imagine having a maintenance window where hundreds of Terraform runs are executed across many different environments and workspaces. Do you really want to have to jump from place to place to figure out how the Terraform runs are doing? The Scalr run dashboards allow you to see all runs across all environments and workspaces in a single place:
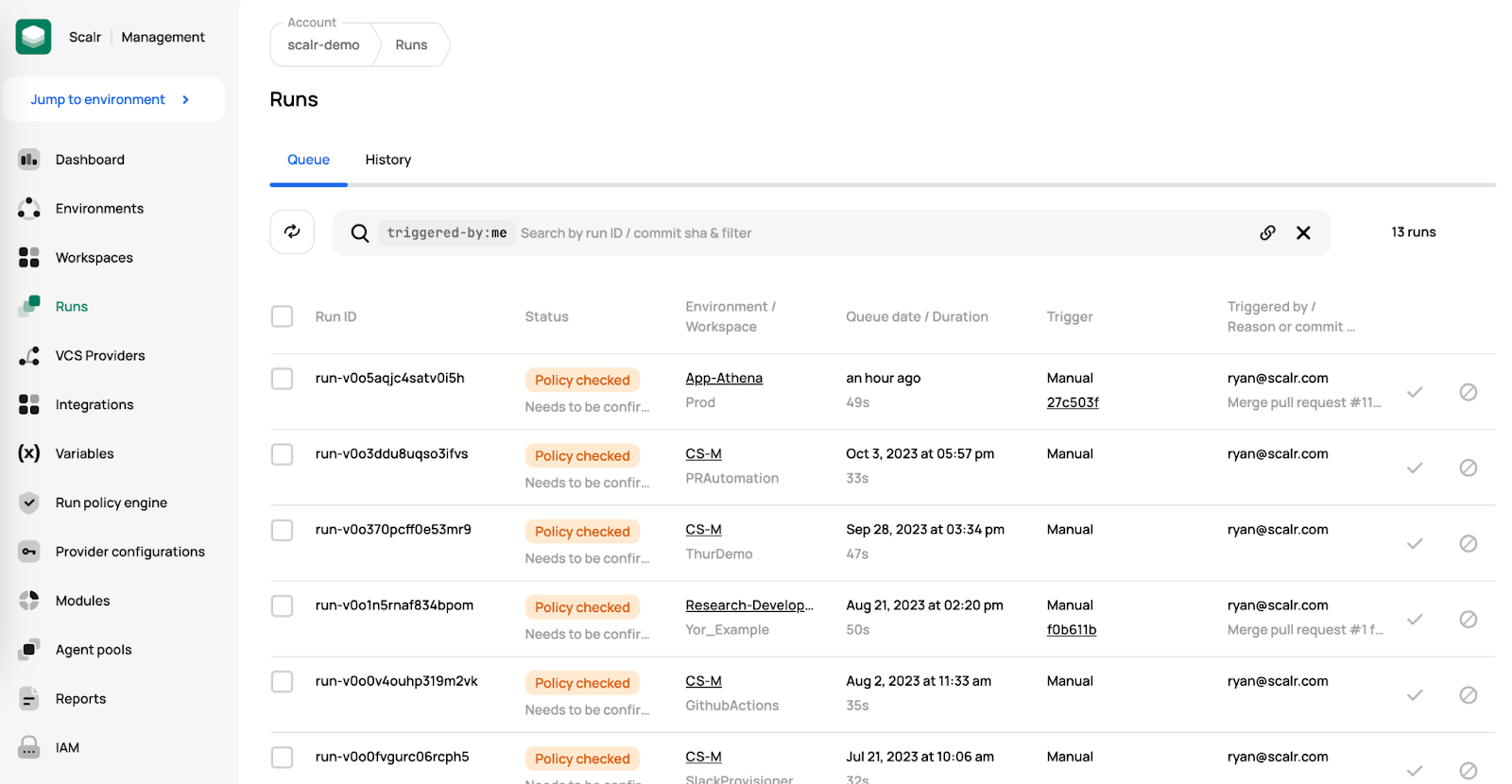
Scalr Run Dashboard
The account scope is really what allows for a platform team to operate Terraform at a large scale efficiently. Not only can you manage all of the objects in a single place, but you can view all Terraform operations and reports as well.
Environment Scope
A Scalr environment is a logical grouping of Terraform workspaces that have a common set of policies, provider credentials, and/or teams assigned to it. We usually see environments aligned to applications, functions, or cloud accounts, such as an AWS account. A workspace, the child of an environment, is where Terraform runs happen, state is stored, environment variables are set, and all settings for the deployments are managed.
The engineers mainly operate at the environment level where workspaces are created and Terraform plans and applies are executed through their own workflows, whether they are through the Terraform CLI, VCS driven, or deployed directly from the private module registry.
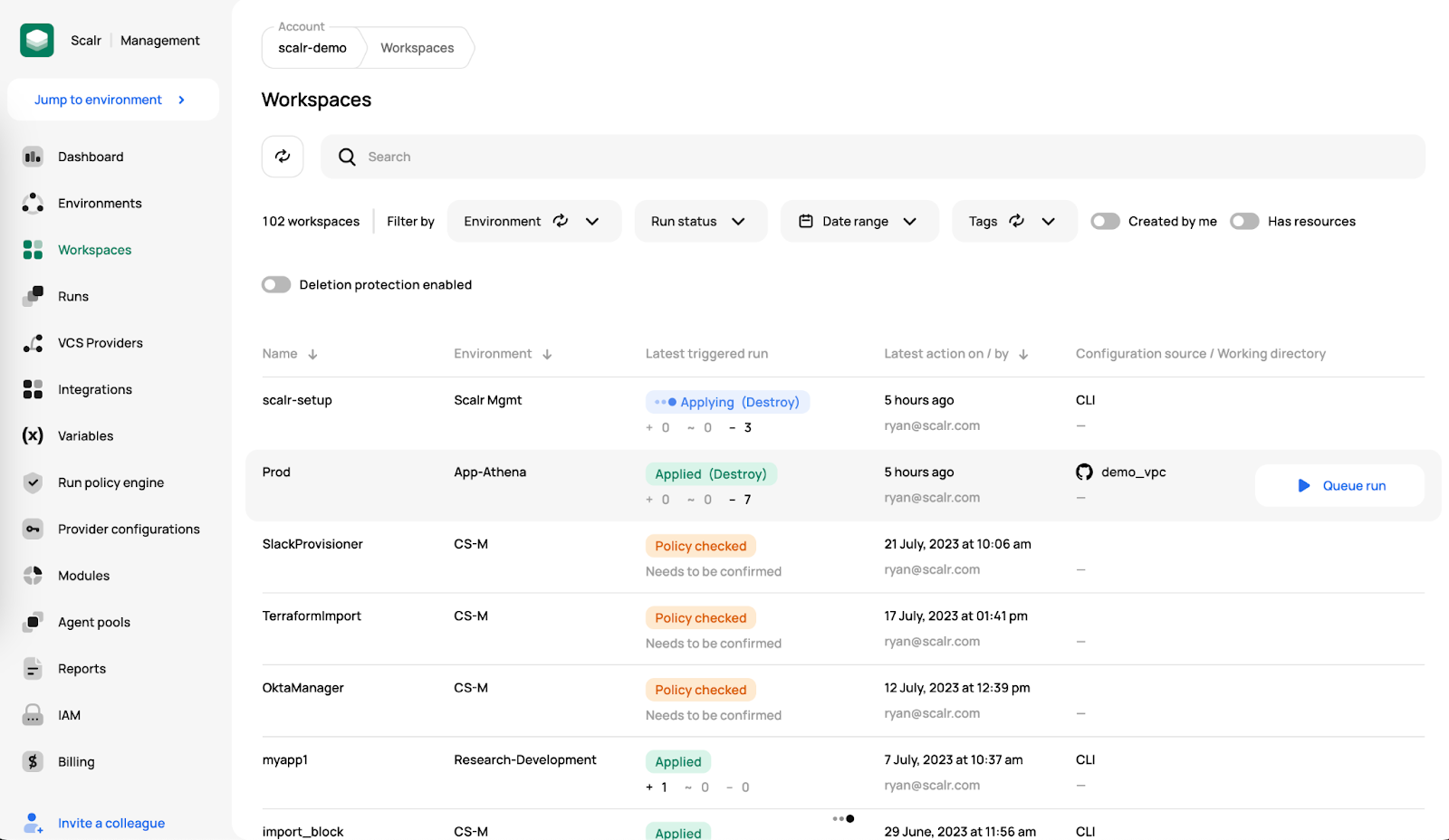
Workspace dashboard
Much like isolated cloud accounts, Scalr environments are isolated areas for teams and users to do their work without impacting other teams. All environments and workspaces will inherit objects that were assigned to it from the account scope. A good example of this is setting a variable, like a tag or region, at the environment scope and having all child workspaces automatically inherit it. The engineers within the environment won't have to worry about setting organizational standards like secrets and variables as they are automatically inherited from the environment or account scope.
The Scalr organizational model makes it very easy to structure your Terraform deployments to ensure engineering teams have isolated environments and the platform team has control and visibility from the account scope.
Follow Your Cloud Provider Model
As we mentioned earlier, environments can be structured many ways, but for most customers, it makes sense to follow the same tenancy model that you use in your cloud providers. The majority of our customers have cloud accounts/subscriptions that equate to a group, an app, etc. Let's use AWS as an example, in AWS you typically have a management account that manages policies, integrations and the child accounts. The child accounts are then mapped to an application where the engineers have the ability to manage their infrastructure.
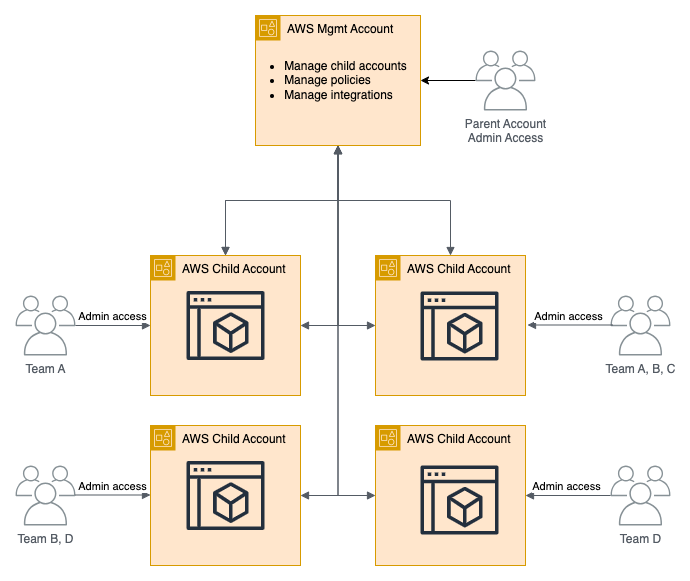
AWS Example
If this concept works for you in AWS, then it's perfectly acceptable to set up Scalr the same way. The Scalr environments would equate to AWS child accounts where the engineers can manage the Terraform workspaces.
In the example below, each group has their own Scalr environment to deploy their Terraform workspaces. Each Scalr environment automatically inherits modules, credentials, OPA policies, and variables based on what the platform team assigns. For example, if the Terraform modules from the account scope are being used, the team can then inject their own additional variables directly into the workspace configuration to reuse the code without having to write it themselves. Having everyone in an organization be proficient in writing Terraform modules would be great, but giving engineers the ability to reuse existing code is the scalable option. Through the environment structure, the engineers have complete autonomy over their environment and workspaces, resulting in decentralization of the Terraform operations.
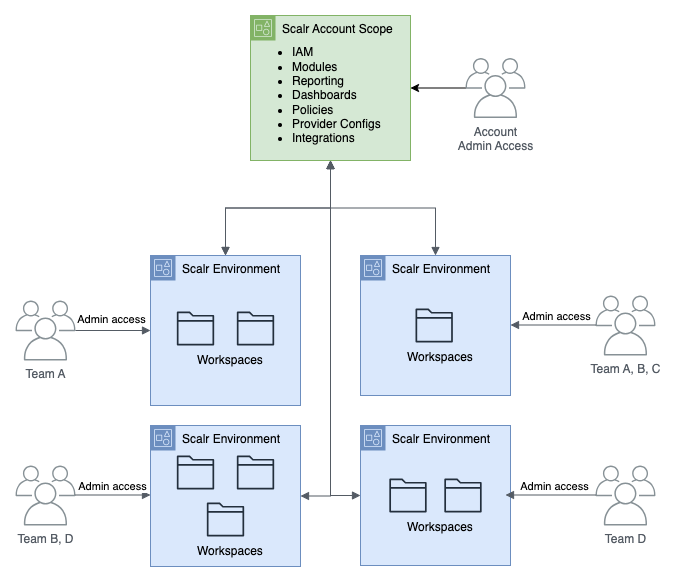
AWS Implementation in Scalr
Next, you will need to figure out what a workspace means for your organization. This is more subjective, but we have seen an increasing trend to have more workspaces with a smaller amount of Terraform resources allowing for quick deployments and easy troubleshooting. Do you give the freedom to pick the workspace source: a VCS provider, the Terraform CLI, or deploy a No Code workspace from the private module registry? All sources can be validated through an OPA policy. As a best practice, standard Terraform modules should be used to reduce the amount of code duplication with the only thing changing being the variable files that are injected at the workspace level.
Just like the AWS account structure, the Scalr account and environment structure is extremely useful in helping isolate your teams and giving them the freedom they need while not increasing operational overhead.
Summary
The writing of the Terraform code is not necessarily the hard part. The scaling of the Terraform operations is the very hard part and if not done correctly the first time, you'll find yourself putting stop gaps in place over and over as inefficiencies are found. There are a couple of key takeaways:
- Use a remote backend, like S3, or even better, a remote operations backend, like Scalr or Terraform Cloud, to centralize Terraform operations.
- An organizational model that allows for objects to be shared or inherited reduces overhead.
- A model that also rolls up all of the operational information whether it's Terraform module usage or how the current Terraform operations are performing increases the platform team's efficiency.
- Don't over complicate the structure that is put in place. If you have created a model in your cloud provider that gives your engineers autonomy while the platform team maintains control, use that same model in Scalr.
The Scalr organization structure allows for any organization, complex or not, to scale Terraform and implement best practices.
Give it a try today by signing up!

Terraform State & Backends: The Complete Guide
Learn how to set up and customize Terraform backend configs with terraform init. Step-by-step examples for remote state, workspaces, and CI/CD.